







- ,所以就写成
[内容]
- !
其它的功能,也不用管!这里只分享怎么能采到文章!然后,点击保存配置并预览,如果前面的列表规则跟内容规则都写对了的话,那现在就会预览到内容了!
点击仅保存,如果你要马上采集的话,也可以点击隔壁的保存并马上采集!

时间:2014-07-08 19:51:54 作者:啤酒 阅读:16777215
一个大型的资讯网站,频道N多,网站数据也N多,不可能每一条数据都是由网站管理员一条条的来发的!这时候,为了节约人力物力,采集器就诞生了(做优化的朋友,笔者可不推荐你们使用哦)!下面,笔者就用织梦管理系统自带的采集器来采集一个网站的数据给大家演示一下,采集规则是怎么写的!
织梦管理系统
有权限的帐号
登录织梦管理后台,依次点击
采集>>采集节点管理>>增加新节点>>选择普通文章>>确定


节点名称:随便(注意你要能分清哦,因为节点多了的话,有可能会搞得自己混乱)
目标页面编码:看目标页面的编码(比如我采集的网站的编码就是GB2312)

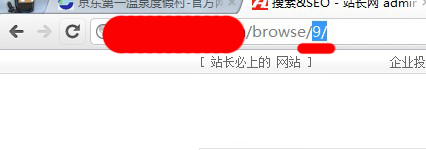
匹配网址:去到采集目标列表页面,查看它的列表规则!比如说很多网站的列表的第一面跟其它内页是有很大的差别的,所以我一般不采集目标列表的第一页!比如说我演示的网站的列表规则是第一页设定一个默认的首页,看不到后面的实际路径的,如图:
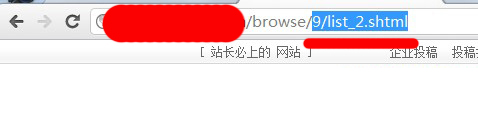
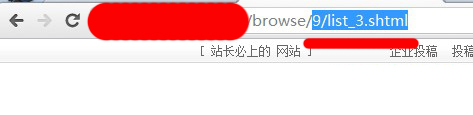
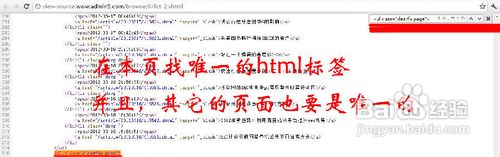
所以,我们只能从第二页开始(虽然可以找出第一页,但很多的网站是根本没第一页的,所以,这里就不说怎么找第一页了),!我们来对比一下,采集目标页的第二页跟第三页!如图:
可以看到,这两页都是有规律的递增的,第二页就是list_2!第三页就是list_3!所以,匹配网址我们就写成
上面那个(*)代表的就是列表页面的2,或3,或4,或更多!而第三条横杆那里,我写了个(*)从 2 到 5 ,这里表示的是,把2到5,每次+1的增加,匹配至(*)里面,代替(*)!

区域开始的HTML:在采集目标列表页打开源代码!在要采集的文章标题前面的附近找一段在本页是唯一并且其它要采集的的页面也是唯一的html标签!
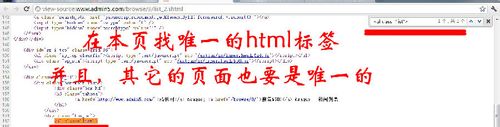
区域结束的HTML:在采集目标列表页打开源代码!在要采集的文章标题后面的附近找一段在本页是唯一并且其它要采集的的页面也是唯一的html标签!
其它的地方,暂时我们还没用到,可以不管!这样,列表页的规则就写好了!下图是我写好的列表规则截图!
写好了,点击保存信息并进入下一步!如果写正确了规则的话,那这些就会出现一个有内容的网址获取规则测试:如下图
再按下一步!进入填写采集内容规则
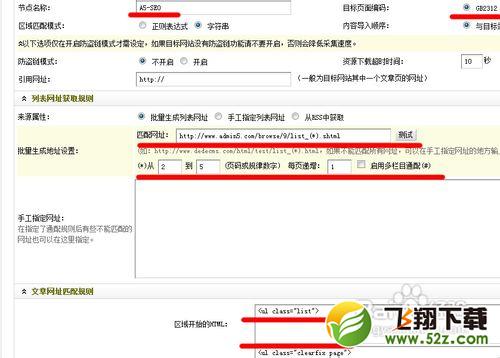

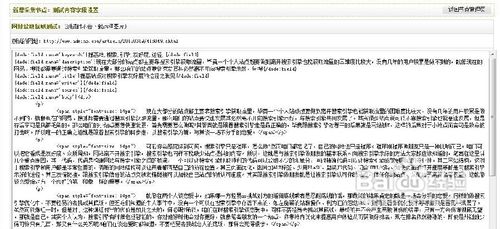
文章标题:在文章标题前后找两个标签,能识别出标题的!我采集的网站的文章标题前后唯一标签是

文章内容:在文章内容前后找两个标签,能识别出内容的!我采集的网站的文章内容前后唯一标签是
其它的功能,也不用管!这里只分享怎么能采到文章!然后,点击保存配置并预览,如果前面的列表规则跟内容规则都写对了的话,那现在就会预览到内容了!
点击仅保存,如果你要马上采集的话,也可以点击隔壁的保存并马上采集!
火车头 Thomas Game Pack V1.114.8MB
下载火车头 Thomas Game Pack V1.114.8MB
下载火车头 Thomas Game Pack V1.114.8MB
下载火车头 Thomas Game Pack V1.114.8MB
下载火车头 Thomas Game Pack V1.114.8MB
下载
一个大型的资讯网站,频道N多,网站数据也N多,不可能每一条数据都是由网站管理员一条条的来发的!这时候,为了节约人力物力,采集器就诞生了(做优化的朋友,笔者可不推荐你们使用哦)!下面,笔者就用织梦管理系统自带的采集器来采集一个网站的数据给大家演示一下,采集规则是怎么写的!
16777215